
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- join
- 제약조건
- 렐루함수
- 최댓값
- 신경망
- 오차제곱합
- 학습 구현
- 데이터베이스
- 합계
- 밑바닥부터 시작하는 딥러닝
- PyQt5
- sigmoid
- sum
- 시험데이터
- max
- 평균
- 교차엔트로피오차
- total
- AVG
- Depthwise Convolution
- Next.js
- MIN
- sqlite3
- Depthwise Separagle Convolution
- 수치미분
- 미니배치
- PYTHON
- COUNT
- Pointwise Convolution
- next.js 튜토리얼
- Today
- Total
우잉's Development
Mask R-CNN 논문 리뷰 본문
제 처음 포스팅할 논문은 Mask R-CNN입니다. 이제 막 딥러닝 논문을 시작하려는 제가 Mask R-CNN을 보기엔 다른 논문 또는 개념들이 부족합니다. 계속 추가적으로 공부하고 포스팅하며 관련 포스팅도 추가하고 수정하면서 공부할 계획입니다. 잘못된 부분이 있거나 궁금하신 사항 있으시면 언제든지 댓글 부탁드립니다.
자! 그럼 저의 첫 논문 리뷰 스터디를 시작하겠습니다!
Mask R-CNN논문을 리뷰하기 전에 instance segmentation에 대해 짚고 넘어가겠습니다.
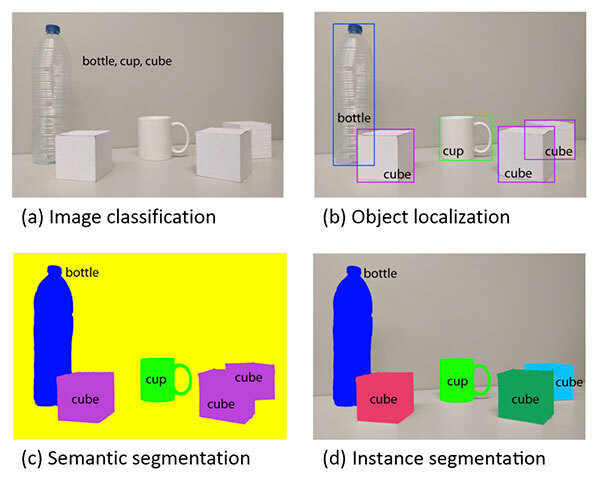
a) 사진에서는 이미지에 있는 object를 bottle, cup, cube로 분류
b) 사진에서는 그 object들이 어디에 위치해 있는지 표시
c) 사진에서는 b에서 좀 더 세심하게 틀을 표시, cube는 다같은 보라색으로 표시
d) 사진에서는 c와 달리 cube를 각각 다른 cube로 표시 (instance 구분)
- instance segmentation : 이미지 내 존재하는 모든 object를 탐지하는 동시에 각각의 instance를 정확하게 pixel단위로 분류.
즉, instance segmentation = object detection task + segmatic segmentation task
Introduction
Mask R-CNN 구조
: Faster R-CNN의 RPN에서 얻은 RoI(Region of Interest)에 대해 객체의 class를 예측하는 classification branch와
bounding box regression을 수행하는 bounding box regression branch와 평행으로 segmentation mask를 예측하는
mask branch를 추가한 구조
mask branch
: 각각의 RoI에 작은 크기의 FCN(Fully convolution Network)가 추가된 형태, segmentation task를 보다 효과적으로
수행하기 위해 논문에서는 객체의 spatial location을 보존하는 RoIAlign layer를 추가
- RoI (Region of Interest) : 이미지나 영상 내에서 내가 관심있는 부분
Mask R-CNN
Faster R-CNN
1 stage : RPN(Region Proposal Network), bounding object box를 제안
2 stage : bounding object box에서 RoIPool을 사용하여 특성을 추출하고 classification과 bbox regression을 수행
Mask R-CNN
1 stage : RPN에서 RoI를 얻습니다.
2 stage : RoI, feature map을 통해 classfication, bbox regression, segmentation mask를 동시에 사용합니다. 그로인해 loss함수로 multi loss를 가지게 됩니다.
loss function : \(L\) = \(L_{cls}\) + \(L_{box}\) + \(L_{mask}\)
\(L_{cls}\) : classfication loss (softmax cross entropy)
\(L_{box}\) : bounding box loss(Regression)
\(L_{mask}\) : mask loss(binary cross entropy)
mask에서는 하나의 픽셀에 대해 각각 class별로 해당 클래스의 instance가 존재하는지 안하는지 sigmoid를 통해 binary로 계산
mask branch에서는 각각의 RoI에 대해 각각의 클래스 k에 대해 binary mask를 계산합니다.
binary mask란 아래의 그림처럼 특정 클래스 k에 대해 instance가 있다고 생각되면 1, 없으면 0으로 나타냅니다.

Mask R-CNN에서는 이전의 instance segmentation모델과 다르게 class별로 mask를 생성후 픽셀당 class에 해당하는지
여부를 표시합니다. 이는 mask와 class prediction을 분리(논문에서 decouples라 표현) 한다는 의미입니다.
mask branch는 최종적으로 \(K^2m\)크기의 feature map을 출력합니다.
\(m\) : feature map의 크기 , \(K\) : class의 수
RoIAlign
RoI pooling을 사용하면 입력 이미지 크기와 상관없이 고정된 크기의 feature map을 얻을 수 있다는 장점있지만 논문에서는 추출된 feature와 RoI 사이가 어긋나는 misalignment가 발생한다고 합니다. 이것은 마스크를 예측하는데 부정적 영향이 있을 수 있습니다. 이를 해결하기 위해서 우리는 RoI Pool의 quantization(양자화)을 제거하고 추출된 feature와 적절하게 aligning하는 RoIAlign layer을 제안합니다.
(Quantization 양자화 : 실수형 변수(floating-point type)를 정수형 변수(integer or fixed point)로 변환하는 과정)
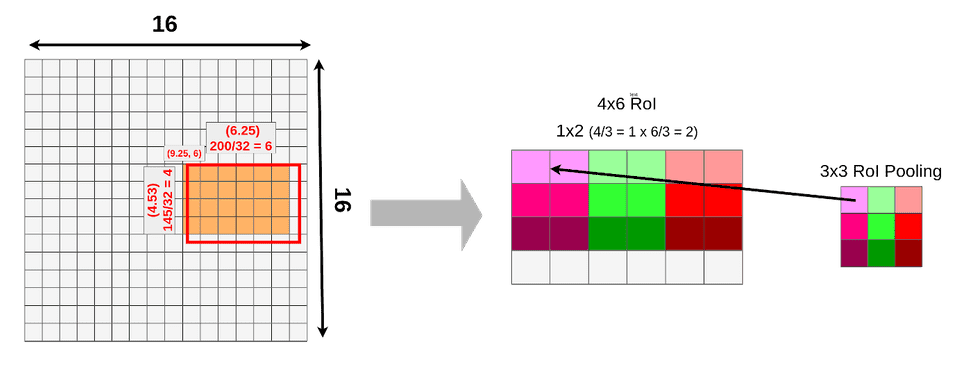
RoI를 backbone network에서 추출한 feature map의 크기에 맞게 투영(projection)하는 과정이 있습니다. 위의 그림의 경우 RoI크기는 145 x 200이며, feature map은 16 x 16입니다. 이를 sub sampling ratio(=512/16=32)에 맞게 나눠주면 feature map은 4.53x6.25크기를 가지게 됩니다. 하지만 픽셀 미만의 크기로 분할 하는 것은 불가능 하기 때문에 크기를 4 x 6크기의 feature map을 얻을 수 있습니다.
이제 4 x 6 크기의 feature map을 3x3크기의 feature map을 얻기위해 RoI Pooling을 수행합니다. stride는 1 x 2로 설정됩니다.
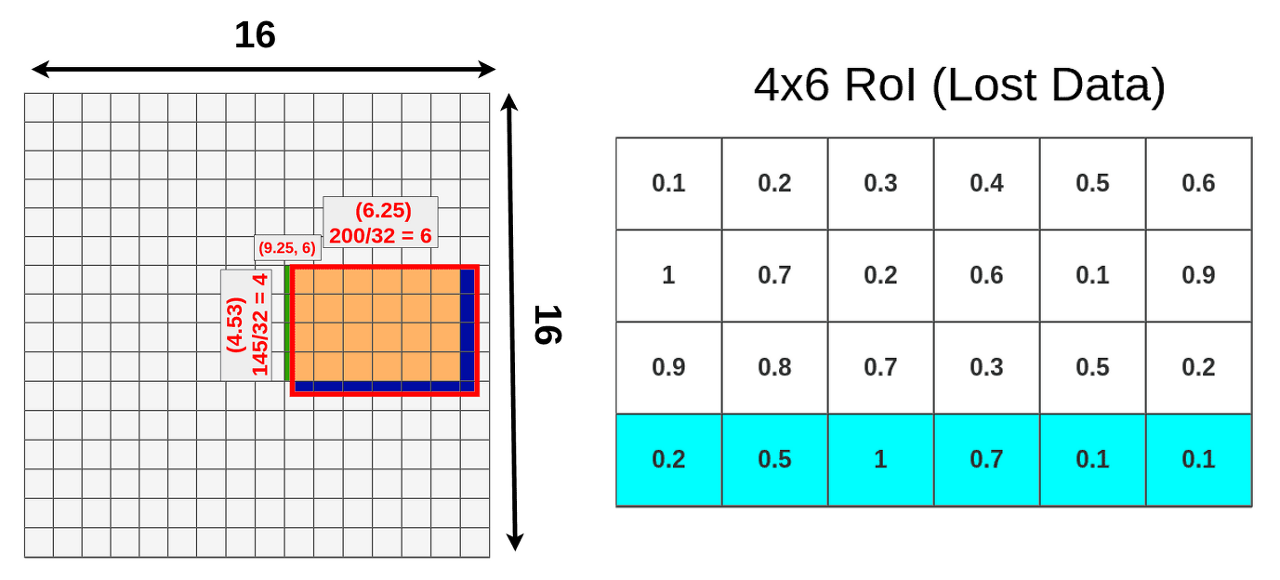
위 그림에서 RoI Pooling 실행 하면 quantization(양자화)로 인해 소실되는 정보를 보여주고 있습니다.
왼쪽 그림에서는 초록생과 파란색 부분이 RoI projection 수행과정에서 소수점부빈이 반올림되면서 정보가 손실되는 것을 알 수 있습니다. 오른쪽 그림은 RoI Pooling시 stride를 반올림하게 되면서 feature map의 마지막 형광하늘색 정보가 손실됨을 알 수 있습니다.
RoIAlign의 방법
1) RoI projection을 통해 얻은 feature map을 quantization과정 없이 그대로 사용합니다.
아래와 같이 3x3의 feature map을 출력한다고 가정하고 너비와 높이를 각 각 3등분을 해서
9개의 셀을 만듭니다.

2) 각 cell의 height, width를 다시 3등분하여 4개의 sampling포인트를 찾습니다.
(위 그림에 파란색점이 sampling point)
3) Bilinear interpolation을 적용하여 sampling point을 추정합니다.
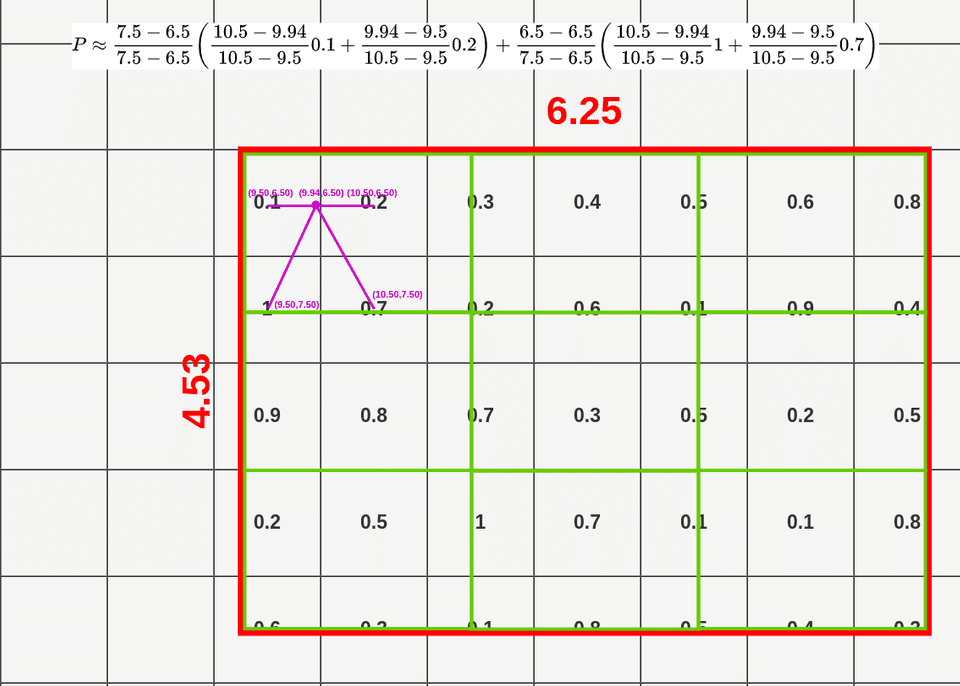
4) 하나의 셀에 있는 sampling point에 대하여 max pooling을 수행.

참고: https://towardsdatascience.com/understanding-region-of-interest-part-1-roi-pooling-e4f5dd65bb44
Experiments
Main Result

위의 표에 나타나듯이 COCO2015 및 2016 세분화 챌린지에서 우승한 MNC와 FCIS 그리고 FCIS+++보다
ResNet-101-FPN백본을 사용한 Mask R-CNN의 성능이 더 뛰어 나다는것을 알 수 있습니다.

이번 그림에서는 FCIS+++과 Mask R-CNN 비교입니다. FCIS+++에서는 중복되는 instance에 대한 artifacts에 비해
Mask R-CNN은 instance 세분화의 어려움이 없는것을 확인 할 수 있습니다.
Ablation Experiments
1)Architecture

네트워크가 깊을수록 성능이 더 좋습니다.
C4보다는 FPN이, 그리고 ResNet보다는 ResNeXt가
성능이 좋습니다.
2) Multinmial vs Independent Masks
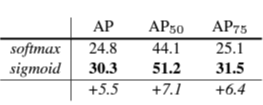
mask와 class예측(mask branch)를 분리했을때 성능이
더 좋습니다.
3) RoIAlign

RoIPool과 RoIWarp보다 RoIAlign을 사용했을 때 성능이 더 좋습니다.
pixel-level에서 masking을 수행하기 때문에 위치 정보를 적절히 유지하는 것이 중요함
4) Mask Branch

mask prediction에 MLP보다 FCN을 사용하는 것이 좋은 성능을 보입니다.
FCN은 공간 레이아웃을 명시적으로 인코딩하기 때문에 pixel-to-pixel task에서 좋은 성능을 보입니다.
Bounding Box Detection Results

Timing
: COCO trainval35k에서 RestNet-50-FPN은 32시간, ResNet-101-FPN으로 44시간이 걸립니다.
훈련속도가 빠릅니다.
여기까지 처음 논문을 리뷰해보았습니다. 모르는 용어는 클릭하면 용어정리로 넘어갈 수 있게 파란색으로 해놓았습니다.
안되어있다고 아는건... 아니구요.. 조금씩 채워나가도로고 하겠습니다.
고럼 다음시간에는 MobileNet을 진행해보도록 하겠습니다! 많이 부족하지만 읽어 주셔서 감사합니다.
'Deep learning > 논문' 카테고리의 다른 글
| MobileNet 논문 리뷰 (0) | 2022.01.28 |
|---|---|
| MobileNet 논문 리뷰 (0) | 2022.01.21 |
